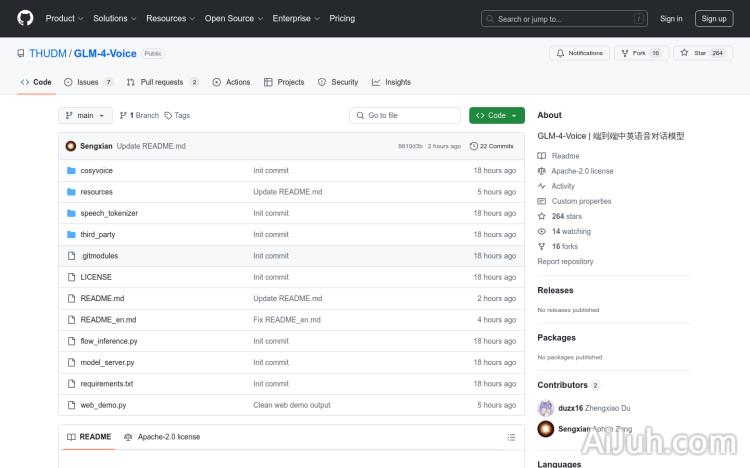
GLM-4-Voice官网
GLM-4-Voice是由清华大学团队开发的端到端语音模型,能够直接理解和生成中英文语音,进行实时语音对话。它通过先进的语音识别和合成技术,实现了语音到文本再到语音的无缝转换,具备低延迟和高智商的对话能力。该模型在语音模态下的智商和合成表现力上进行了优化,适用于需要实时语音交互的场景。
GLM-4-Voice是什么
GLM-4-Voice是由清华大学团队开发的一款端到端中英语音对话模型。它能够直接理解和生成中英文语音,实现实时语音对话,并具备低延迟和高智商的对话能力。该模型集语音识别、语音合成于一体,支持情感控制,并进行了针对语音模态智商和合成表现力的优化,非常适合需要实时语音交互的场景。
GLM-4-Voice的主要功能
GLM-4-Voice的主要功能包括:语音识别(将语音转换为文本)、语音合成(将文本转换为语音)、实时中英文对话、情感控制(调节语音的情感、语调、语速和方言)、流式推理(降低延迟)以及多语言支持。
如何使用GLM-4-Voice
使用GLM-4-Voice需要以下步骤:
- 下载仓库: 使用git命令克隆项目到本地。
- 安装依赖: 根据
requirements.txt文件安装所需的Python依赖。 - 下载模型: 下载所需的语音模型和分词器。
- 启动模型服务: 运行
model_server.py脚本启动模型服务。 - 启动Web Demo: 运行
web_demo.py脚本启动Web Demo服务。 - 访问Web Demo: 在浏览器中访问
http://127.0.0.1:8888来使用Web Demo。
GLM-4-Voice的产品价格
目前关于GLM-4-Voice的价格信息并未公开,建议访问其GitHub页面或联系清华大学相关团队获取详细信息。
GLM-4-Voice的常见问题
GLM-4-Voice的运行环境要求是什么?
需要安装Python以及requirements.txt中列出的所有依赖项。具体配置要求请参考GitHub项目页面。
GLM-4-Voice支持哪些类型的语音输入?
GLM-4-Voice支持连续语音输入,并能识别多种口音和语速。
如果在使用GLM-4-Voice时遇到错误,该如何解决?
请仔细检查步骤,确保已正确安装依赖项并下载模型。如果问题仍然存在,请参考GitHub项目页面上的文档或提交问题。
GLM-4-Voice官网入口网址
https://github.com/THUDM/GLM-4-Voice
OpenI小编发现GLM-4-Voice网站非常受用户欢迎,请访问GLM-4-Voice网址入口试用。
数据统计
数据评估
本站Home提供的GLM-4-Voice都来源于网络,不保证外部链接的准确性和完整性,同时,对于该外部链接的指向,不由Home实际控制,在2025年 1月 9日 下午11:17收录时,该网页上的内容,都属于合规合法,后期网页的内容如出现违规,可以直接联系网站管理员进行删除,Home不承担任何责任。