














MV-Adapter官网
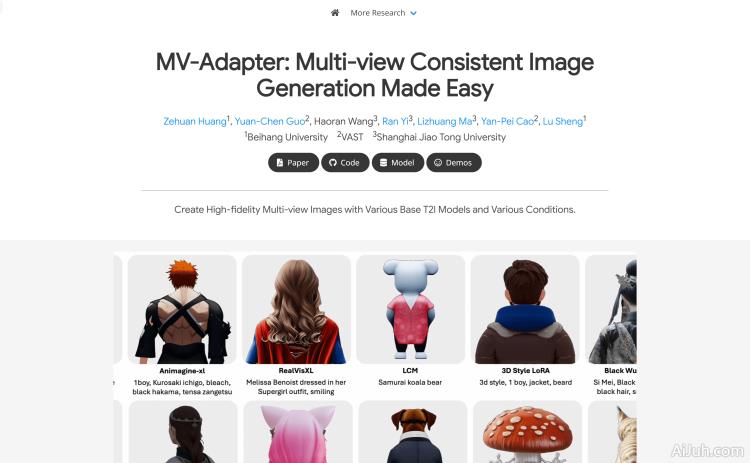
MV-Adapter是一种基于适配器的多视图图像生成解决方案,它能够在不改变原有网络结构或特征空间的前提下,增强预训练的文本到图像(T2I)模型及其衍生模型。通过更新更少的参数,MV-Adapter实现了高效的训练并保留了预训练模型中嵌入的先验知识,降低了过拟合风险。该技术通过创新的设计,如复制的自注意力层和并行注意力架构,使得适配器能够继承预训练模型的强大先验,以建模新的3D知识。此外,MV-Adapter还提供了统一的条件编码器,无缝整合相机参数和几何信息,支持基于文本和图像的3D生成以及纹理映射等应用。MV-Adapter在Stable Diffusion XL(SDXL)上实现了768分辨率的多视图生成,并展示了其适应性和多功能性,能够扩展到任意视图生成,开启更广泛的应用可能性。
MV-Adapter是什么?
MV-Adapter是一个基于适配器的多视图图像生成解决方案,它能够增强预训练的文本到图像模型,例如Stable Diffusion XL,使其能够生成多视角一致的图像,而无需大幅修改原有模型结构。它通过添加一个轻量级的适配器模块来实现这一功能,这个模块学习如何将3D几何信息和相机参数融入到图像生成过程中,从而生成从不同角度观看同一场景的图像。简单来说,它就像一个“插件”,可以轻松地添加到现有的文本到图像模型中,赋予其多视图生成能力。
MV-Adapter的主要功能
MV-Adapter的核心功能在于生成多视图一致性图像。这意味着它可以生成从多个不同角度拍摄的同一场景的图像,并且这些图像在视角、光线、物置等方面保持一致。其主要功能包括:
- 多视图图像生成: 从文本或图像提示生成多个不同视角的图像。
- 3D几何知识建模: 利用复制的自注意力层和并行注意力架构,有效地理解和生成3D场景。
- 统一条件编码器: 整合相机参数和几何信息,支持更精细的控制。
- 高分辨率生成: 支持768分辨率的图像生成。
- 适配器式设计: 无需对预训练模型进行大规模修改,易于集成。
如何使用MV-Adapter?
使用MV-Adapter相对简单,主要步骤如下:
- 从GitHub下载MV-Adapter的模型和代码。
- 阅读文档,了解配置要求和参数设置。
- 设置环境,安装必要的依赖库(例如PyTorch)。
- 将下载的代码和模型文件放置在正确的目录。
- 运行代码,输入文本或图像提示,以及相机参数等信息。
- 查看生成结果,并根据需要调整参数以优化图像质量。
MV-Adapter的产品价格
目前官网未提供MV-Adapter的具体价格信息,它更像是一个开源的工具或研究项目,可以免费获取和使用。但是,使用过程中可能需要一定的计算资源,例如强大的GPU,这会产生相应的成本。
MV-Adapter的常见问题
MV-Adapter的系统要求是什么?
MV-Adapter需要一定的计算资源才能运行,具体取决于你想要生成图像的分辨率和复杂程度。至少需要一个支持CUDA的NVIDIA显卡,以及足够的内存和存储空间。建议参考官方文档中的系统要求。
如何调整MV-Adapter的参数以获得更好的图像质量?
MV-Adapter提供了许多参数可以调整,例如采样步数、学习率、噪声强度等。建议仔细阅读文档中对参数的说明,并通过实验来找到最佳的参数组合。通常,增加采样步数可以提高图像质量,但也会增加计算时间。
MV-Adapter支持哪些类型的预训练模型?
目前,MV-Adapter主要在Stable Diffusion XL上进行了测试和验证,但其适配器式设计原则上可以应用于其他类型的文本到图像扩散模型。具体的兼容性信息,请参考官方文档或GitHub项目页面。
MV-Adapter官网入口网址
https://huanngzh.github.io/MV-Adapter-Page/
OpenI小编发现MV-Adapter网站非常受用户欢迎,请访问MV-Adapter网址入口试用。
数据统计
数据评估
本站Home提供的MV-Adapter都来源于网络,不保证外部链接的准确性和完整性,同时,对于该外部链接的指向,不由Home实际控制,在2025年 1月 9日 下午9:24收录时,该网页上的内容,都属于合规合法,后期网页的内容如出现违规,可以直接联系网站管理员进行删除,Home不承担任何责任。





