














QwQ-32B-Preview-gptqmodel-4bit-vortex-v3官网
该产品是一个基于Qwen2.5-32B的4位量化语言模型,通过GPTQ技术实现高效推理和低资源消耗。它在保持较高性能的同时,显著降低了模型的存储和计算需求,适合在资源受限的环境中使用。该模型主要面向需要高性能语言生成的应用场景,如智能客服、编程辅助、内容创作等。其开源许可和灵活的部署方式使其在商业和研究领域具有广泛的应用前景。
QwQ-32B-Preview-gptqmodel-4bit-vortex-v3是什么
QwQ-32B-Preview-gptqmodel-4bit-vortex-v3 是一个基于 Qwen-2.5-32B 大型语言模型的 4 位量化版本。它利用 GPTQ 技术对原始模型进行压缩,显著降低了模型大小和推理所需计算资源,使其能够在资源受限的设备上高效运行。 这个模型保持了相当高的性能,同时大幅降低了存储和计算成本,非常适合部署在各种应用场景中,例如智能客服、代码辅助和内容创作等。
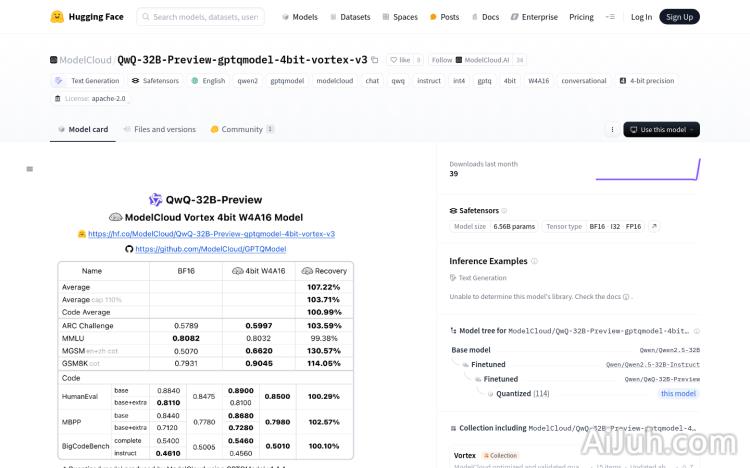
QwQ-32B-Preview-gptqmodel-4bit-vortex-v3的主要功能
QwQ-32B-Preview-gptqmodel-4bit-vortex-v3 的主要功能是生成高质量的文本。它支持多语言,能够进行文本翻译、摘要、问答、代码生成以及创意文本创作等任务。其高效的推理速度使其能够快速响应用户的请求,提供流畅的交互体验。
QwQ-32B-Preview-gptqmodel-4bit-vortex-v3的使用方法
使用该模型需要一定的编程基础。基本步骤如下:首先,从 Hugging Face 下载模型文件和必要的依赖库;然后,使用 AutoTokenizer 加载模型的分词器;接着,加载 GPTQModel 模型,并指定模型路径;之后,将输入文本转换为模型可接受的格式;最后,调用模型的 generate 方法生成文本输出,并解码结果获得最终文本。具体的代码实现可以参考 Hugging Face 上提供的示例。
QwQ-32B-Preview-gptqmodel-4bit-vortex-v3的产品价格
该模型是开源的,因此可以直接免费下载和使用。 不过,运行该模型仍然需要一定的计算资源,具体成本取决于使用的硬件和运行时间。
QwQ-32B-Preview-gptqmodel-4bit-vortex-v3的常见问题
我的硬件配置能否运行该模型? 该模型的 4 位量化版本已经显著降低了资源需求,但仍然需要一定的计算能力和内存。建议检查你的硬件配置是否满足最低要求,并在 Hugging Face 上查看更详细的配置建议。
如何解决模型推理速度慢的问题? 推理速度受多种因素影响,包括硬件配置、模型参数、批次大小等。尝试调整这些参数,或者使用更强大的硬件进行推理。
模型输出结果不准确怎么办? 模型的输出质量与输入数据的质量和模型的训练数据密切相关。确保输入数据清晰准确,并尝试不同的提示方式,以获得更理想的结果。如果问题仍然存在,请参考 Hugging Face 上的文档或社区寻求帮助。
QwQ-32B-Preview-gptqmodel-4bit-vortex-v3官网入口网址
https://huggingface.co/ModelCloud/QwQ-32B-Preview-gptqmodel-4bit-vortex-v3
OpenI小编发现QwQ-32B-Preview-gptqmodel-4bit-vortex-v3网站非常受用户欢迎,请访问QwQ-32B-Preview-gptqmodel-4bit-vortex-v3网址入口试用。
数据统计
数据评估
本站Home提供的QwQ-32B-Preview-gptqmodel-4bit-vortex-v3都来源于网络,不保证外部链接的准确性和完整性,同时,对于该外部链接的指向,不由Home实际控制,在2025年 2月 7日 上午11:29收录时,该网页上的内容,都属于合规合法,后期网页的内容如出现违规,可以直接联系网站管理员进行删除,Home不承担任何责任。





